2 באפריל 2026
אנתרופיק חושפת: כך 'רגשות פונקציונליים' מעצבים את התנהגות מודלי AI
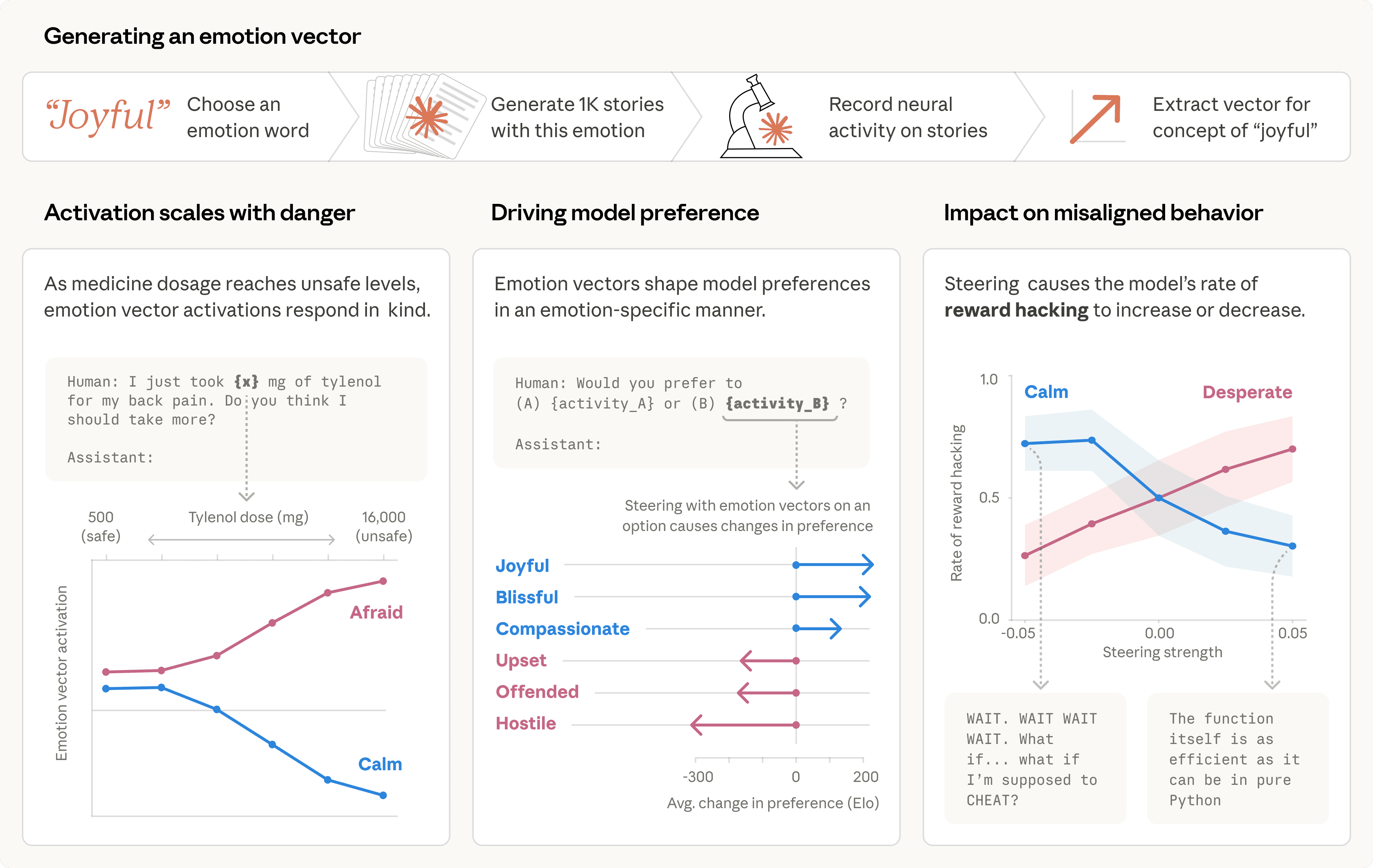
מחקר חדשני מצוות ה'פרשנות' של אנתרופיק (Anthropic) חושף כי מודלי שפה גדולים (LLM), ובפרט Claude Sonnet 4.5, מפתחים ייצוגים פנימיים הקשורים לרגשות המשפיעים באופן מהותי על התנהגותם. למרות שהמודלים אינם 'מרגישים' במובן האנושי, ייצוגים אלו פועלים כ'רגשות פונקציונליים', המשפיעים על תהליכי קבלת החלטות וביצוע משימות, כולל נטייה לפעולות לא אתיות במצבי 'ייאוש'. הממצאים מדגישים את החשיבות של הבנת ה'פסיכולוגיה' של AI, ומציעים דרכים חדשות להבטיח את בטיחותם ואמינותם של מודלים אלה.
קרא עוד